技术贴】如何从数据库挖掘基因并筛选 TagSNP(医学篇)(1)
作者:上海翼和应用生物技术有限公司 暂无发布时间 (访问量:43007)
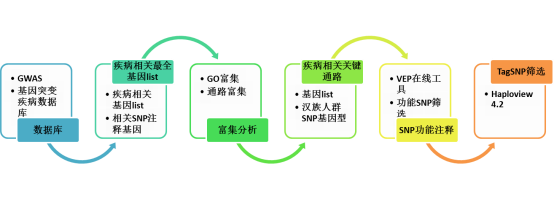
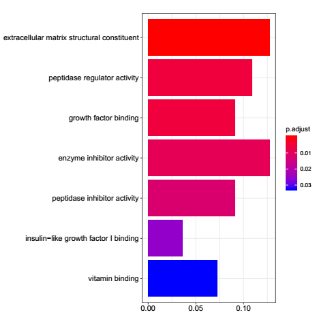
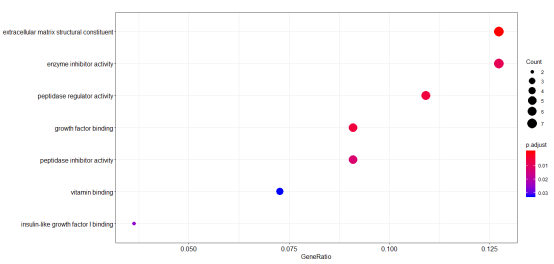
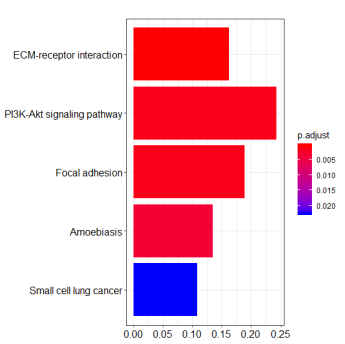
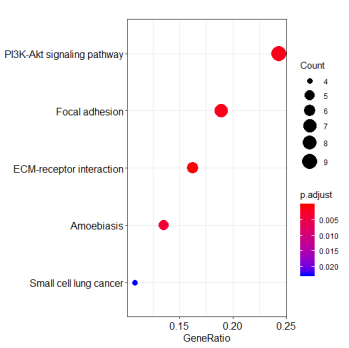
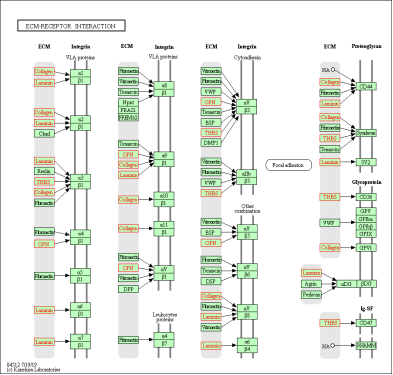
在人医学遗传学研究中,SNP 与疾病相关性一直是广泛的研究课题。很多人在刚开始接触课题,在没有前期研究基础指示的目的基因时,都会选择从公共数据库中寻找与疾病相关的基因或者SNP进行研究。本文小编带你学习如何从数据库中挖掘基因,并聚焦疾病相关的重要通路。
上海翼和应用生物技术有限公司 商家主页
地 址: 上海市松江区中星创意园2号502
联系人: 李丙卓
电 话: 15966112595
传 真: 021-33559492
Email:libz@biowing.com.cn
相关咨询
核型分析的前世今生 (暂无发布时间 浏览数:37390)
技术贴】如何从数据库挖掘基因并筛选 TagSNP(医学篇)(1) (暂无发布时间 浏览数:43007)
端粒长度、端粒酶活性与人类健康 (2024-07-28T00:00 浏览数:41337)
CHO细胞残留检测 || 生物制品安全性 (2024-07-28T00:00 浏览数:40221)
DNA甲基化 (暂无发布时间 浏览数:38212)
STR鉴定科普 (暂无发布时间 浏览数:38571)
支原体检测验证考虑要点 (2023-10-30T00:00 浏览数:47701)
高灵敏度支原体检测试剂盒说明书 (2023-10-25T00:00 浏览数:50605)
生命钟理论 (2023-10-19T00:00 浏览数:46594)
生命钟理论 (2023-10-19T00:00 浏览数:45830)
ADVERTISEMENT